- Data
Technical Blog: Global Forest Watch’s 2018 Data Update Explained

Aaron Minnick
Lee en Español aqui. Baca dalam Bahasa di sini. Lire en Français ici. Leia em Portugues aqui.
New data shows that tropical forest loss continued at a high rate in 2018. Below we answer several frequently asked questions related to the annual tree cover loss dataset on Global Forest Watch that are important to understanding the nuances of the data.
What does tree cover loss measure?
The University of Maryland’s (UMD) annual tree cover loss data set measures the removal of at least half of tree cover within a 30-meter pixel (also known as stand replacement disturbance). This measurement does not determine between permanent land cover change (deforestation) or temporary loss (in which forests will recover), or between natural or human causes of loss. Forest degradation, caused by dynamics like selective logging and fires, is also sometimes captured within the annual tree cover loss dataset if it has a large enough impact on the tree canopy.
What is the time period of the dataset?
The tree cover loss dataset includes annual loss for each calendar year between 2001 and 2018. Because optical satellite data collection can often be obscured by cloud cover in the humid tropics, some late-in-the year loss can be picked up in the next year following persistent cloud cover. This is a common occurrence in Indonesia and many other tropical countries where cloud cover is prevalent, which is why we recommend using a three-year moving average to assess totals and trends in the tree cover loss data.
Our graphs this year focus on the period 2002-2018 because we are using the primary forest dataset (dated to 2001) as a base.
Is the data methodology consistent throughout the time series?
The current tree cover loss data uses one algorithm covering 2001-2010 and another covering 2011-2018. We advise caution when comparing loss numbers from these two time periods, as the newer version of the dataset may be more sensitive to changes related to small-scale agriculture, fires, and other forms of forest degradation. For example, 2016/2017 saw a large spike in tree cover loss due to fires. While this appears to be an anomaly in the data, it is possible that other fire events pre-2011 had a large impact and were not detected due to the algorithm. UMD is planning to reprocess all previous years of the tree cover loss data using one algorithm, but until then, we cannot know for sure how comparable the two algorithms are to each other.
What is primary forest?
This year, for first time ever, we have data on the extent (as of 2001) of tropical humid primary forests, areas of natural, mature forest cover that have not been cleared and regrown in recent history (less than 30-50 years). The dataset was created by the University of Maryland using Landsat imagery and remote sensing algorithms to identify low albedo and high texture primary forest canopy structures. Primary forest is mapped at 30 meter resolution, with no minimum patch size. Some post-algorithm hand editing was done to remove spectrally inseparable non-primary forest land covers, such as tree plantations. Forests that experienced selective logging may or may not be included in the primary forest dataset. Forests with loss due to roads and intensive logging activities are likely not counted as primary forests, while forests with selective logging leading to only partial canopy removal at the 30 meter resolution may be included. Other types of primary forest were not included in this dataset, meaning countries like Madagascar, with high amounts of dryland forest ecosystem, have additional primary forest loss that is not included in the humid primary forest statistics.
What is primary forest loss?
To determine primary forest loss, we look only at those 30 by 30 meter pixels of tree cover loss that occurred within the primary forest extent. Using the primary forest data as a filter for tree cover loss allows us to focus on changes in those forests that are most important for carbon and biodiversity and exclude tree cover loss associated with the rotation of tree crops or timber plantations. Importantly, we can also assume that any loss in primary forests results in a reduction of the total primary forest extent, as these areas do not regenerate on a scale of twenty years.
Primary forest loss may still include removals of canopy cover by human or natural causes, including fire, and does not necessarily indicate deforestation (the permanent conversion of forests to another land use, like agriculture or urban areas). As mentioned above, methodology changes in 2011 may lead to inconsistencies between the 2002-2010 data and the 2011-2018 data.
How does the UMD annual tree cover loss data in Brazil compare to official estimates?
The UMD annual tree cover loss data has differed from PRODES, Brazil’s official monitoring system, in the last few years.
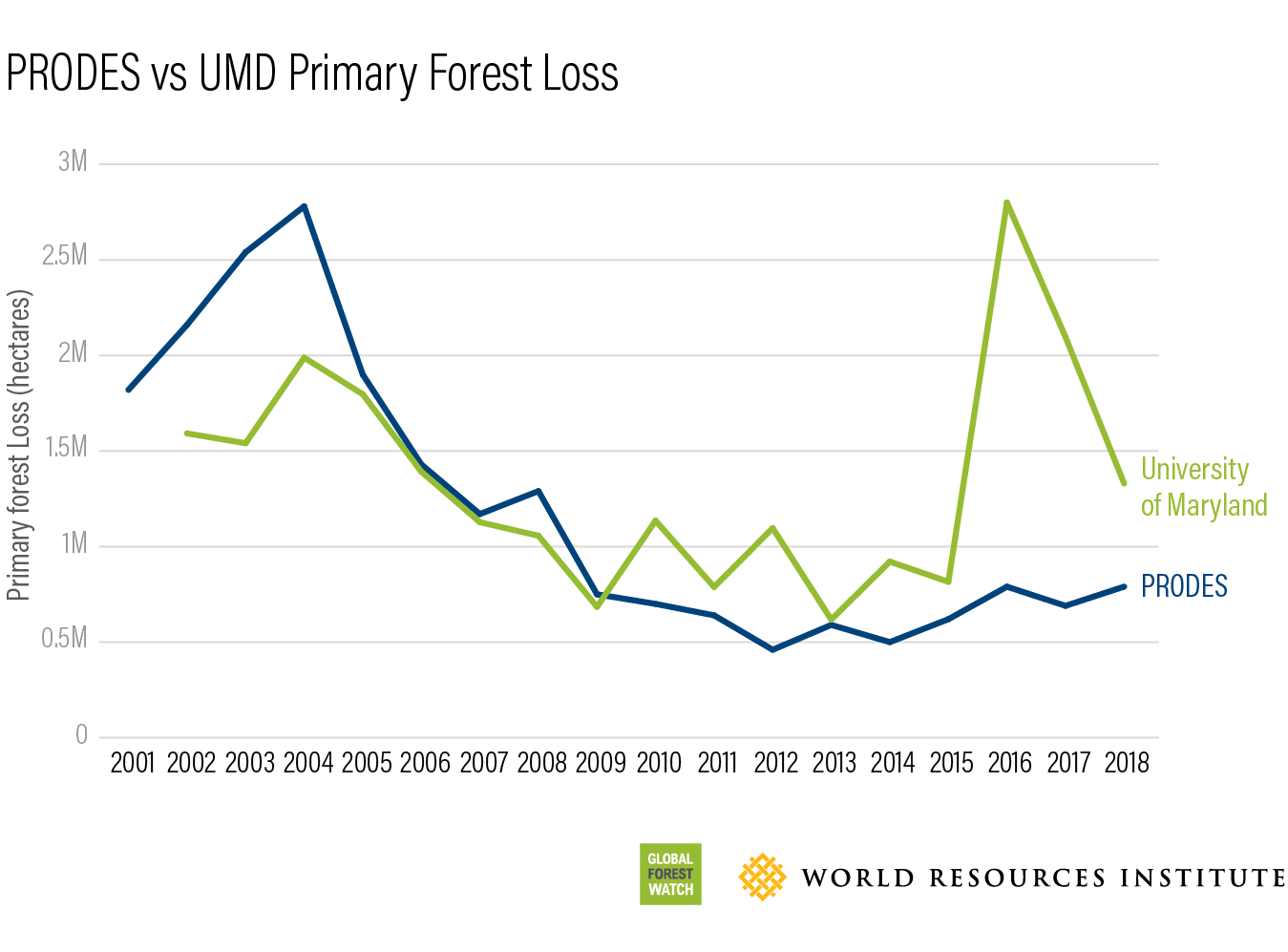
The two systems may seem at odds, but really they measure two different, but important types of changes in forests. PRODES focuses on large clear-cutting of primary forest in the Amazon, while the UMD data captures loss in all tree cover, including loss in secondary forest, forest degradation from fires, and loss as small as 0.1 hectares. UMD also uses January to December to capture loss, while PRODES uses August to July.
PRODES, which began in 1988 when most of the Amazon was still primary forest, does not account for change in secondary forests. Areas identified as deforestation in previous years are no longer considered as primary forest, allowing for reliable measurement of only new clear-cut areas in the Amazon. This methodology helps when accounting for carbon emissions from deforestation, as it assumes that all forest carbon is emitted the first time a natural forest area is clear-cut and avoids the need to estimate carbon sequestration from forest regrowth, as well as emissions from secondary forest losses. The new primary forest data allows us to filter the UMD tree cover loss data to better approximate the PRODES numbers, but the two datasets still diverge in recent years.
Last year, we showed that these methodological differences explained the discrepancies in the two datasets for 2017. We replicated the PRODES methodology using the UMD’s tree cover loss data again this year to see if that remained true in 2018. To do so, we limited the scope of the analysis to only those areas considered in the PRODES analysis (primary forests in Brazil’s legal Amazon), removed loss overlapping with the MODIS burned area product, and filtered out any loss patches smaller than 6.25 hectares (PRODES’ minimum patch size). This resulted in a total of 0.68 million hectares of loss according to the UMD data, compared to the preliminary 2018 loss statistic from PRODES of 0.79 million hectares in the Amazon.
Our analysis shows these definitional and methodological differences are at the heart of the discrepancy between the two datasets. Both are important for understanding forest dynamics in the Brazilian Amazon and, importantly, both have shown an increase in forest loss from the low point in 2012/2013.
BANNER PHOTO: Leaf detail. Photo by Aaron Minnick/WRI.
Explore More Articles



Explore More Articles







